Les systèmes d’écriture manuscrites informatique se faisaient déjà en Asie (principalement Chine et Japon), via des tablettes graphiques spécialisée dans l’écriture manuscrite, depuis les années 1980 et à côté de nombreuses méthodes de saisie au clavier. En Europe et dans le domaine du logiciel libre, il aura fallu attendre la fin des années 1990 pour qu’apparaissent les premier systèmes de saisie de ce type, et attendre un peu plus longtemps pour que cela se démocratise. Ces méthodes peuvent également servir aux personnes n’ayant plus de main et ne pouvant donc taper sur clavier, mais pouvant en utilisant les pieds la bouche ou différents autres systèmes tenir un outil d’écriture plus traditionnel comme un stylo ou un pinceau.
* Kanjipad (site en anglais) est probablement le plus ancien (depuis 1997) système de reconnaissance d’écriture sous Linux et logiciels libres, mais il ne semble plus très actif.
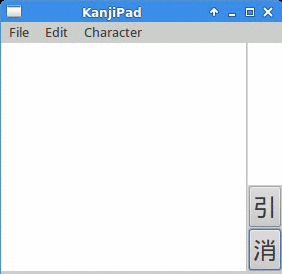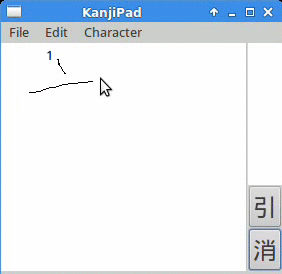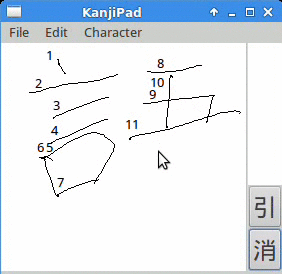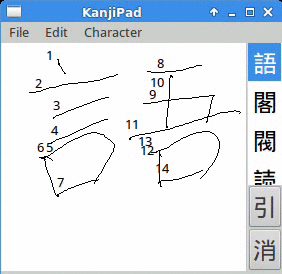
D’autres solutions libres sont arrivés depuis dans les écosystèmes à sources ouvertes.
* Cellwriter, (aux environs de 2007) à une méthode plus générale qui nécessite un apprentissage par l’utilisateur via le remplissage répétitif d’une ligne de caractères. Cela en fait une méthode adaptée à n’importe quelle langue, mais si le remplissage est rapide pour les écritures alphabétiques limitées à quelques dizaines de caractères, c’est beaucoup, plus fastidieux pour des langues pictographiques on basées sur des combinaisons de caractères à deux dimension comme le chinois Han, comportant des milliers de caractères. Un apprentissage séparés des caractères pictographiques, sous leur forme brute, sous forme de clé et dans les combinaisons les plus courante pourrait accélérer le processus d’apprentissage. D’autres écritures chinoises comme le Dongba sont purement pictographique, cela nécessite donc l’apprentissage de milliers de caractères sans aucune autre solution. Voir également la très bonne documentation succincte sur l’excellent wiki doc.Ubuntu-fr.org.
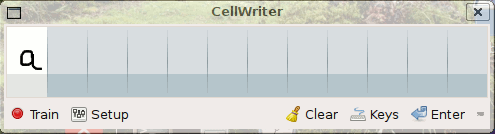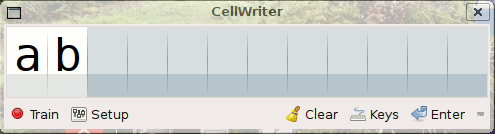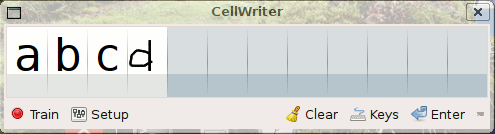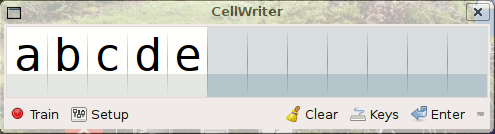
Apprentissage dans Cellwriter (Crédit : doc.ubuntu-fr.org)
Projets les plus actifs dans le domaine de la saisie manuscrite sous Linux
* Tomoe (en anglais et japonais) un gestionnaire de reconnaissance manuscrite qui avance régulièrement.
* Stroke-editor (en anglais), par Huzheng (en chinois), le concepteur de l’excellent et toujours référence, Stardict(en anglais et chinois), dictionnaire multilingue libre. Stroke Editor permet de faire de l’apprentissage d’écriture qui serviront à nourrir le serveur de Tomoe.
* Tegaki (anglais), spécialisé dans la reconnaissance manuscrite du Chinois et du Japonais, il utilise plusieurs moteurs ; Zinnia (anglais et japonais) et Wagomu (développé par les auteurs de Tegaki) et le plus expérimental KanjiVG. Tegaki à l’avantage d’avoir une interface à l’excellent iBus, moteur de méthodes de saisie complexe le plus standard et comportant le plus de méthodes sous Linux.

Si ils ont été crées à l’origine pour les Hanzi, (caractère han en chinois, également appelés kanji en Japonais, hanja en Coréen, hán tự en Vietnamien,…), ils sont également capable d’analyser la majorité des écritures de la planète. Mise à jour 27 septembre : Il y a des problèmes dans certains cas pour reconnaître les caractères du type de 道 (dao, « la voie », le taoïsme, aussi utilisé sous la prononciation « do » en japonais, « karate do », ‘ « bushi do », etc…). Quelqu’un proposait une solution en 2010 sur un forum sur le cantonais (en anglais), qui consistait à mettre à jour la base (au format XML) de ce caractère. Il semble que tous les caractères contenant la clé 廴 / 辵 soit affectés. Contrairement à l’ordre chinois, il faut ici écrire la clé avant le contenu, ce qui semble être l’ordre japonais. Je me demande comment ils peuvent faire de la belle calligraphie dans ces conditions, mais bon…
En ligne
* qhanzi
* kanji.sljfaq
En java, je n’ai donc pas testé
* Hanzi Recognizer, spécialisé hanzi chinois, un jar en java qui sert également de dictionnaire.
* Hanzidict également dictionnaire + saisie manuscrite en java.